概念
并查集是一种树形的数据结构,顾名思义,它用于处理一些不交集的 合并 及 查询 问题。 它支持两种操作:
- 查找(Find):确定某个元素处于哪个子集;
- 合并(Union):将两个子集合并成一个集合。
结构
在理解上并查集是一个森林,但是在实际实现上位了方便将其简化成数组。
理解上的结构
结构
每棵树代表一个子集,根节点用来标记这个子集
操作
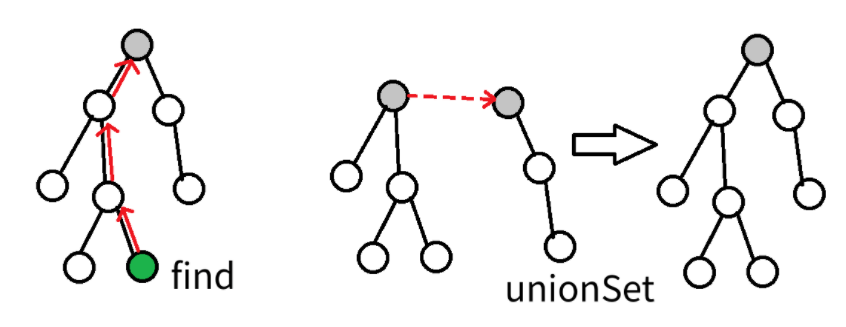
- find:递归查找父节点,最终得到标记子集的根节点(祖先)
- union:将两棵树合并(不必在意细节,因为实现时使用数组)
实际的实现
结构
我们使用一个parent数组来存储对应索引的父亲的索引
1 | //初始化代码,一开始每个节点一个子集,自己的父亲为自己 |
操作
- find操作,递归查找父节点,最终得到标记子集的根节点(祖先)
1 | public int find(int x) { |
- union操作,合并子集
1 | //使两个集合拥有相同的祖先 |
优化
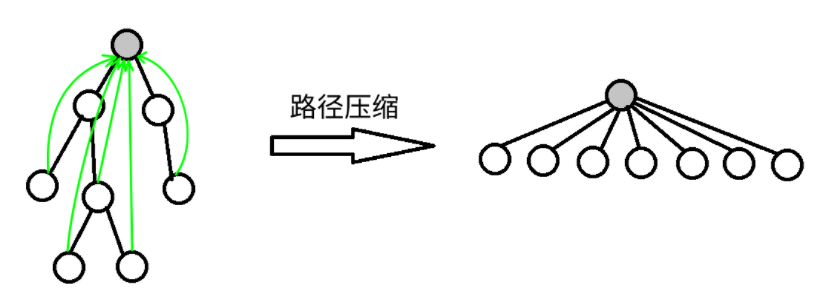
路径压缩
概念
把每个节点都直接连接到根上 ,这就是路径压缩(把递归查找祖先的路径压缩)
实现
1 | public int find(int x) { |
启发式合并(按秩合并)
概念
简单来说在合并时将深度(或者节点个数)较小的合并子集到较大的子集中去
需要一个rank数组来粗略的记录深度(主要是为了方便,没必要精确记录深度)
实现
1 | //初始化rank数组 |
总体实现
1 | private class UnionFind { |